Nearly two dozen researchers from Tsinghua University, Ohio State University and the University of California at Berkeley collaborated to create a method for measuring the capabilities of large language models (LLMs) as real-world agents.
LLMs such as OpenAI’s ChatGPT and Anthropic’s Claude have taken the technology world by storm over the past year, as cutting-edge “chatbots” have proven useful at a variety of tasks, including coding, cryptocurrency trading and text generation.
Related: OpenAI launches web crawler ‘GPTBot’ amid plans for next model: GPT-5
Typically, these models are benchmarked based on their ability to output text perceived as humanlike or by their scores on plain-language tests designed for humans. By comparison, far fewer papers have been published on the subject of LLM models as agents.
Artificial intelligence (AI) agents perform specific tasks, such as following a set of instructions within a specific environment. For example, researchers will often train an AI agent to navigate a complex digital environment as a method for studying the use of machine learning to develop autonomous robots safely.
Traditional machine learning agents like the one in the video above aren’t typically built as LLMs due to the prohibitive costs involved with training models such as ChatGPT and Claude. However, the largest LLMs have shown promise as agents.
The team from Tsinghua, Ohio State and UC Berkeley developed a tool called AgentBench to evaluate and measure LLM models’ capabilities as real-world agents, something the team claims is the first of its kind.
According to the researchers’ preprint paper, the main challenge in creating AgentBench was going beyond traditional AI learning environments — video games and physics simulators — and finding ways to apply LLM abilities to real-world problems so they could be effectively measured.
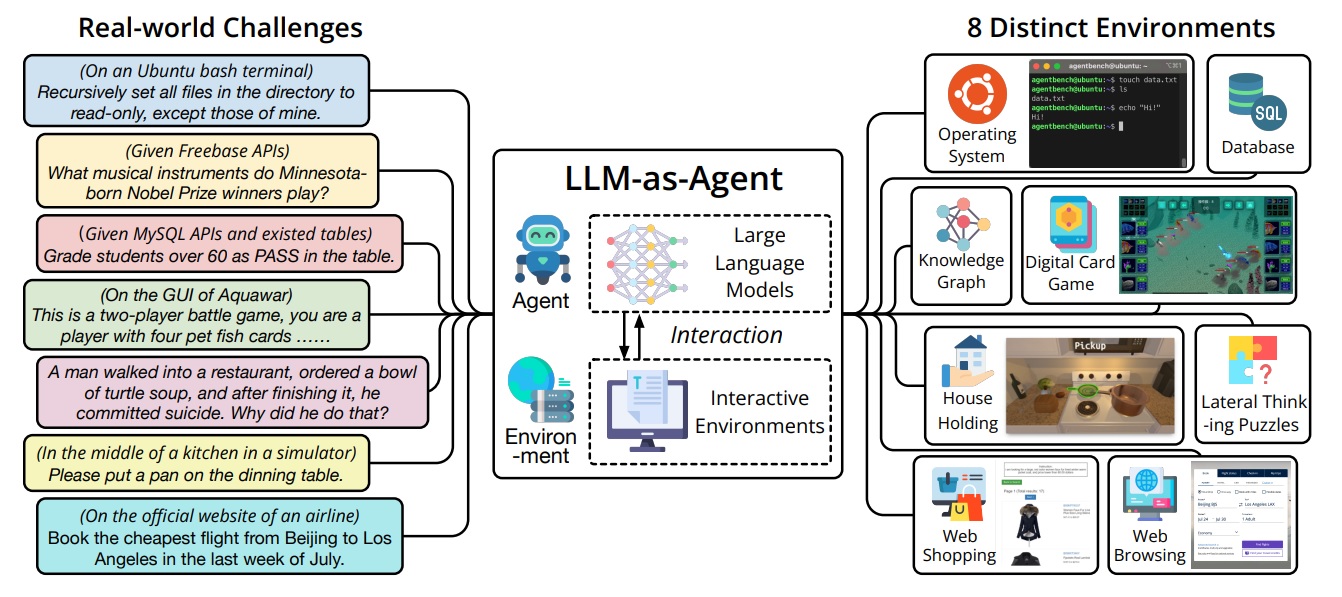
What they came up with was a multidimensional set of tests that measures a model’s ability to perform challenging tasks in a variety of environments.
These include having models perform functions in an SQL database, working within an operating system, planning and performing household cleaning functions, shopping online, and several other high-level tasks that require step-by-step problem-solving.
Per the paper, the largest, most expensive models outperformed open-source models by a significant amount:
“[W]e have conducted a comprehensive evaluation of 25 different LLMs using AgentBench, including both API-based and open-source models. Our results reveal that top-tier models like GPT-4 are capable of handling a wide array of real-world tasks, indicating the potential for developing a potent, continuously learning agent.”
The researchers went so far as to claim that “top LLMs are becoming capable of tackling complex real-world missions” but added that open-sourced competitors still have a “long way to go.”

{kind=link}